Negli ultimi anni abbiamo assistito a un’accelerazione impressionante nel campo dell’intelligenza artificiale. I nuovi modelli linguistici, come GPT-5 o Claude, sono diventati così potenti da gestire compiti complessi, scrivere codice, ragionare in modo strutturato e persino coordinare processi interi.
Eppure, dietro le quinte, resta un limite non banale: lo spazio del prompt.
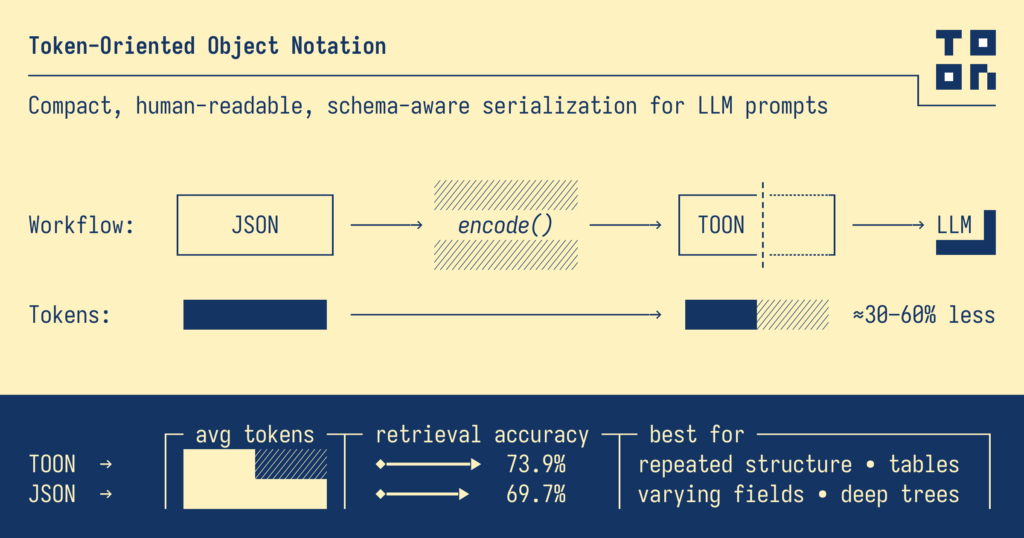
C’è una scena che chi sviluppa con gli LLM conosce bene: vuoi passare dati strutturati al modello, ma JSON ti mangia contesto in parentesi, virgolette e ripetizioni. Risultato? Prompt più lunghi, risposte meno stabili, costi che lievitano.
Negli ultimi mesi è spuntata una proposta interessante: TOON – Token-Oriented Object Notation. È un formato testuale compatto e leggibile pensato per essere “digerito” dai modelli, con una promessa concreta: ridurre i token del 30–60% soprattutto su array uniformi di oggetti, mantenendo però una struttura chiara e validabile. Il progetto è aperto, con spec, benchmark e SDK TypeScript pubblici su GitHub. GitHub
Cos’è TOON (in una frase)
Un JSON “re-immaginato” per gli LLM: indentazione alla YAML per i nidificati, tabellare tipo CSV quando hai molte righe con le stesse chiavi, e pochi segni di punteggiatura. Così il modello legge meglio e consuma meno contesto. GitHub
Il “colpo di scena” di TOON: gli array tabellari
In JSON ripeti le chiavi in ogni riga. TOON dichiara le chiavi una sola volta e poi “streamma” i valori riga per riga.
JSON
{
"users": [
{ "id": 1, "name": "Alice", "role": "admin" },
{ "id": 2, "name": "Bob", "role": "user" }
]
}
TOON
users[2]{id,name,role}:
1,Alice,admin
2,Bob,user
È esattamente lo schema che il repo ufficiale porta come esempio e che spiega gran parte del risparmio. GitHub
Altri esempi TOON “concreti”
1) Dataset clienti (stile tabellare)
clients[3]{id,ragione_sociale,piva,email}:
101,BioFattoria Srl,IT01234567890,info@biofattoria.it
102,TerraViva,IT09876543210,hello@terraviva.eu
103,Orti Uniti,IT11223344556,contatti@ortiuniti.it
2) Config annidate (stile YAML-like)
pipeline:
input:
type: csv
delimiter: ;
steps: normalizza_case, trim_spazi
output:
type: jsonl
pretty: no
3) Istruzioni multi-linea per l’LLM
guidelines: |
- Rispondi in italiano.
- Se un campo manca, restituisci stringa vuota.
- Evita testo extra fuori dallo schema richiesto.
Benchmarks e risultati: cosa dicono i test
Il team TOON pubblica una sezione “Benchmarks” con dataset misti (nidificati, semi-uniformi, tabellari) e test di retrieval accuracy su più modelli. Il messaggio chiave: TOON brilla dove i dati sono uniformi, mentre su strutture profonde o non uniformi il vantaggio può calare, e CSV resta imbattibile per le tabelle piatte. C’è anche un link a un “Format Tokenization Playground” per confrontare i token tra formati con i tuoi dati. GitHub
TOON in Python: come si usa davvero
Il repo ufficiale fornisce SDK TypeScript e specifica. La community, nel frattempo, ha prodotto encoder/decoder in diversi linguaggi (PHP, R, Elixir, Gleam, ecc.) e un encoder Python minimal per serializzare valori JSON-compatibili in TOON. Hexdocs+3GitHub+3GitHub+3
1) Python → TOON (encode)
# Esempio d'uso con un encoder Python community (encode -> stringa TOON)
from toon import encode # dal progetto community "python-toon"
data = {
"users": [
{"id": 1, "name": "Sreeni", "role": "admin", "email": "sreeni@example.com"},
{"id": 2, "name": "Krishna", "role": "admin", "email": "krishna@example.com"},
{"id": 3, "name": "Aaron", "role": "user", "email": "aaron@example.com"},
]
}
toon_str = encode(data)
print(toon_str)
# possibile output (semplificato):
# users[3]{id,name,role,email}:
# 1,Sreeni,admin,sreeni@example.com
# 2,Krishna,admin,krishna@example.com
# 3,Aaron,user,aaron@example.com
(Il pacchetto community “python-toon” espone encode(value, options=None) che serializza oggetti Python JSON-serializzabili). GitHub
2) Dal “dialetto” tabellare a oggetti Python
Se ricevi TOON con header users[3]{id,name,role,email}: e righe CSV-like, puoi ricostruire una lista di dict così:
def rows_to_objects(schema, rows):
out = []
for row in rows:
item = {k: v for k, v in zip(schema, row)}
if "id" in item:
try: item["id"] = int(item["id"])
except: pass
out.append(item)
return out
schema = ["id", "name", "role", "email"]
rows = [
["1", "Sreeni", "admin", "sreeni@example.com"],
["2", "Krishna", "admin", "krishna@example.com"],
["3", "Aaron", "user", "aaron@example.com"],
]
users = rows_to_objects(schema, rows)
# [{'id': 1, 'name': 'Sreeni', ...}, ...]
Nota: diversi encoder/decoder community stanno nascendo in parallelo (PHP, R, ecc.), segno di un interesse cross-linguaggio. Se lavori in ecosistemi non-Python, vale la pena cercare l’implementazione aggiornata per il tuo stack. GitHub
Integrazione nei prompt: pattern consigliati
- Input all’LLM: inserisci TOON in un code fence etichettato
toon, anticipando cosa deve fare il modello e come deve validare. - Output dall’LLM: chiedi espressamente di restituire solo TOON aderente allo schema fornito (con lunghezze e campi).
- Fallback: per dati molto irregolari, dichiara che il modello può rispondere in JSON “compatto”.
Molti esempi pratici di “using TOON in prompts” e una cheatsheet di sintassi sono nel README del progetto. GitHub